MySQL
MODIFY 和 CHANGE 的区别
从功能上而言,两者都可以用于修改表的字段,其中 CHANGE 相较于 MODIFY 而言,多了一个给字段重命名的能力。同时也是由于多的这个能力,导致两者在语法格式上稍有不同:
ALTER TABLE t1 CHANGE col_a col_a BIGINT NOT NULL; # 使用 CHANGE
ALTER TABLE t1 MODIFY col_a BIGINT NOT NULL; # 使用 MODIFY也就是说在使用 CHANGE 的时候,哪怕不涉及重命名,仍需要将字段名写两次。
UNION 和 UNION ALL 的区别
UNION 和 UNION ALL 都可以将两个或多个有相同数量的结果集进行合并,不过也有一点区别:
UNION: 会进行去重;UNION ALL: 会保留重复的数据。
UNION
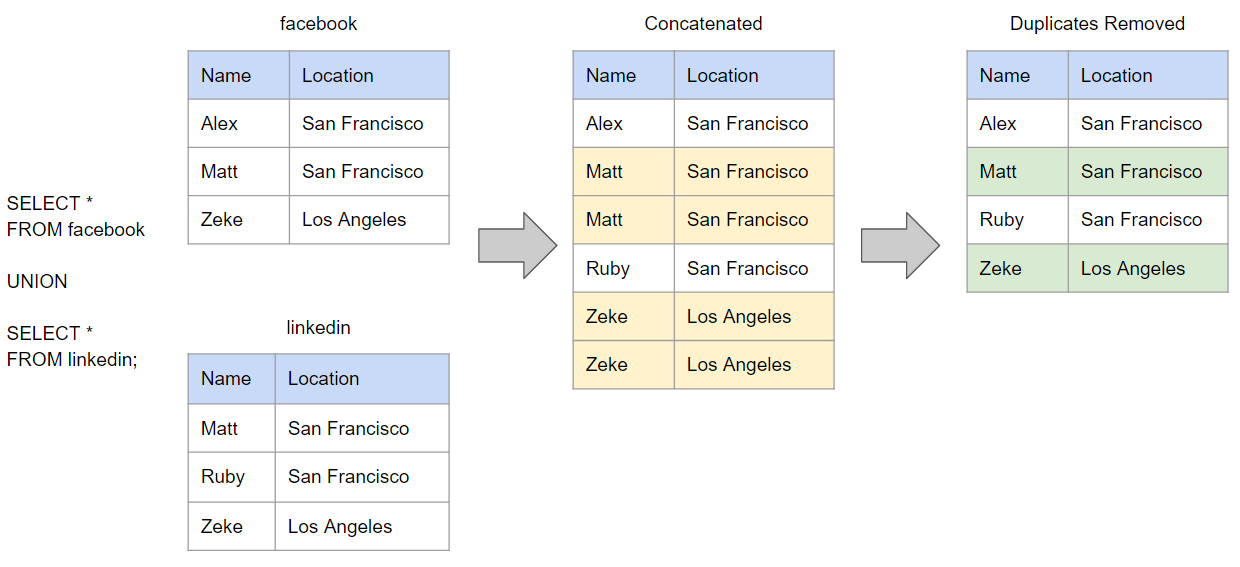
UNION ALL
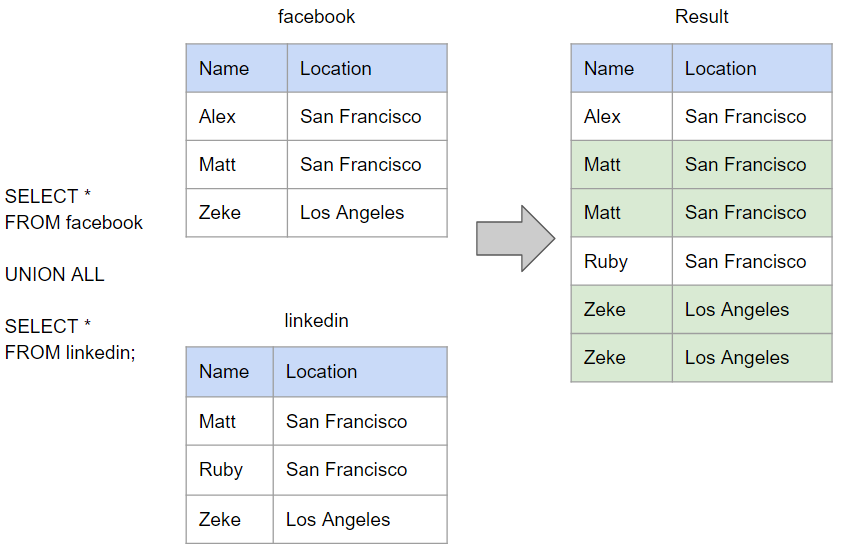
HAVING 语句
HAVING 可以起到与 WHERE 类似的查询作用,不同之处在于 HAVING 可以与聚合函数(SUM/COUNT/MIN/MAX/AVG 等)一起使用,而 WHERE 不行。
-- 统计年薪大于 40 万的员工
SELECT
name,
SUM(month_salary) as year_salary
FROM month_salary_table
WHERE year = 2021
HAVING SUM(month_salary) > 400000;ROLLUP & CUBE
ROLLUP / CUBE 用于聚类汇总数据,可以根据维度在分组的结果集中进行聚合操作,两者仅有细微差别:
- 在只对一个维度进行聚合时,
ROLLUP / CUBE结果是一样的 - 在对多个维度进行聚合时,
CUBE是按所有的可能进行汇总,而ROLLUP是按照指定的顺序进行有优先级地进行汇总:ROLLUP (YEAR, MONTH, DAY)- YEAR, MONTH, DAY
- YEAR, MONTH
- YEAR
- ()
CUBE (YEAR, MONTH, DAY)- YEAR, MONTH, DAY
- YEAR, MONTH
- YEAR, DAY
- YEAR
- MONTH, DAY
- MONTH
- DAY
- ()
使用 ROLLUP / CUBE 汇总数据的行,其列对应的值为 NULL,这时可以借用 GROUPING() 和 CASE ... WHEN ... 替换默认的 NULL 值。
一个完整的例子如下:
SELECT
CASE
WHEN GROUPING(warehouse) = 1 THEN '合计'
ELSE warehouse
END AS warehouse,
SUM(quantity)
FROM
warehouse_quantity_table
GROUP BY ROLLUP (warehouse);NULL 判断
NULL 在数据库中表示空值,在进行比较时,有许多奇特的表现,比如:
-- 与自己比较
SELECT NULL = NULL; -- 结果为 NULL
SELECT NULL != NULL; -- 结果为 NULL
-- 与其他值比较
SELECT 1 = NULL; -- 结果为 NULL
SELECT 1 != NULL; -- 结果为 NULL
SELECT 1 < NULL; -- 结果为 NULL
SELECT 1 > NULL; -- 结果为 NULL总的来说,= / != / > / < 等算术操作符涉及 NULL 时,其结果为 NULL,表示运算无意义。
为了判断 NULL 的值,可以使用 IS NULL 和 IS NOT NULL:
SELECT NULL IS NULL; -- 结果为 1
SELECT NULL IS NOT NULL; -- 结果为 0
SELECT 1 IS NULL; -- 结果为 0
SELECT 1 IS NOT NULL; -- 结果为 1参考文档:MySQL - Working with NULL Values
可能为 NULL 字段的判断
假设我们有一个表 products,其数据如下:
id | name | type
-------------------
1 | product1 | NULL
2 | product2 | NULL
3 | product3 | bad
4 | product4 | good
5 | product5 | good当我们想过滤出不是 bad 类型的产品时,很容易写出来如下的 SQL 语句:
SELECT * FROM products WHERE type != 'bad';然而这种写法只能获取到 id 为 4 / 5 的产品(它们的 type 为 good),而不能获取到 id 为 1 / 2 的产品(它们的 type 为 NULL)。
这种行为在某些情况下是合理的,然后有时也会出乎我们的意料,当我们想要获取到所有不是 bad 类型的产品时(即使 type 为 NULL),可以使用如下的一些方法:
-- 显示判断 NULL
SELECT * FROM products WHERE type IS NULL OR type != 'bad';
-- 使用 <=> 操作符
SELECT * FROM products WHERE NOT type <=> 'bad';
-- 使用 IFNULL 给 type = NULL 场景赋值
SELECT * FROM products WHERE IFNULL(type, '') != 'bad';上述 SQL 可以打开 SQL Fiddle Demo 在线进行测试和验证。
这里介绍下 <=> 操作符,它的名字是 NULL-safe equal,和 = 相似,不过当操作符两边都是 NULL 时返回 1,只有一边是 NULL 时返回 0:
SELECT 1 <=> 1; -- 结果为 1
SELECT 1 <=> NULL; -- 结果为 0
SELECT NULL <=> NULL; -- 结果为 1